
An era ends quietly. No press conference. No exploding X takes.
Just a paper — Titans: Learning to Memorize at Test Time — dropped by Google Research in January 2025. Paired with the MIRAS framework in December, it rewrites the rules of how AI models actually work.
Here’s the brutal truth: Every LLM you’ve ever used has had amnesia.
It forgets between conversations. It can’t learn. It can’t adapt. And the current workarounds — stuffing your entire context window with RAG, paying for billion-token retrieval systems — are like using a fire hose to water a plant. Drowning the system in data hoping it finds the signal.
Titans changes that. And if you’re not thinking about this shift now, you’re going to be playing catch-up when everyone else is already building on test-time learning.
Part 1: What’s Actually Different (And Why Your Brain Should Care)
The Problem Nobody Talks About Clearly
Transformers — the architecture behind GPT, Gemini, Claude, Grok — are stateless machines. They consume input, produce output, and forget everything immediately. Every conversation starts from zero. That’s not a feature; it’s a fundamental limitation.
Current “workarounds” expose this:
- RAG (Retrieval-Augmented Generation) throws thousands of tokens of context into every query, hoping the model will find the needle in the haystack. You’re paying for compute waste.
- Context windows (now 1M+) sound impressive until you realize LLMs only effectively use the first 10–20% of what you give them. The rest is expensive padding.
- Fine-tuning requires retraining the entire model on your data. That’s 2–6 weeks, thousands in compute costs, and your model is *still* locked in time.
Nobody wins. The model is bloated. You’re paying for noise. And AI developers are manually stitching together janky “memory” layers that don’t actually teach the model anything.
Enter Titans: Neural Memory That Learns at Inference Time
Google’s insight: What if the model could update its own weights while talking to you?
Not retroactively. Not through retraining. Right now, during the conversation.
Titans introduces a hybrid architecture with three tiers of memory:
- Short-Term (Core Attention): The standard Transformer mechanism. High precision, immediate context. Like your working memory — what you’re thinking about right now.
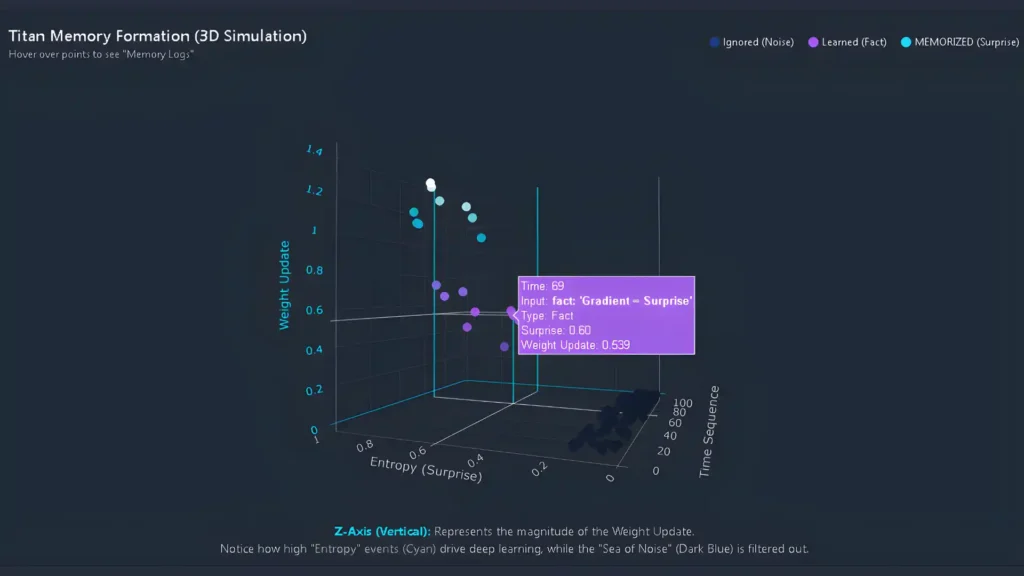
- Neural Long-Term Memory: A deep neural network module that updates its internal parameters at inference time using a metric called “ Surprise.” When you tell the model something unexpected (high gradient), it treats it as a learning event and encodes it.
- Persistent Memory: Fixed, learned parameters. Your cortical knowledge. The hard-wired rules, math, coding patterns, domain facts.
The secret sauce: The Surprise Metric. The model measures how shocked it is by your input (gradient of the loss). Boring inputs (predictable) don’t get memorized. Anomalies, new information, contradictions — those get written into neural memory for the session (or longer).
It’s not magic. It’s Hebbian learning baked into inference. Neurons that fire together wire together.
Part 2: The MIRAS Framework — Google Just Made this Generalize-able
One paper is interesting. A framework that unifies RNNs, Transformers, and Titans? That’s a shift.
In December 2025, Google released MIRAS (Meta-learning for Instruction-tuned Retrieval & Adaptive Sequence models). It’s their blueprint for the next generation of sequence modeling.
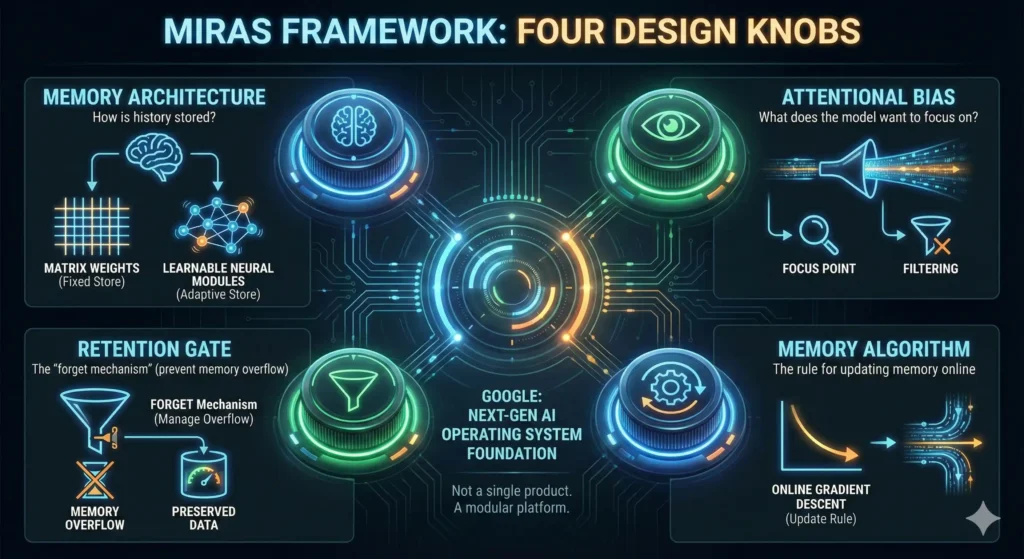
MIRAS says: Memory architecture is a choice, not a law of physics.
Four design knobs:
- Memory Architecture: How is history stored? (Matrix weights vs. learnable neural modules)
- Attentional Bias: What does the model want to focus on?
- Retention Gate: The “ forget mechanism” (prevent memory overflow)
- Memory Algorithm: The rule for updating memory online (e.g., Online Gradient Descent)
Translation: Every architecture that comes next will have these four decisions embedded in it.Gemini 2.0, Claude 4, Llama 4 — they’re all going to be “MIRAS-compliant.”
Google isn’t releasing a single product. They’re releasing the operating system for next-gen AI.
Part 3: The Roadmap (What’s Coming, When)

Phase 1: Research Validation (2025 — DONE)
✅ Titans paper released (January 2025)
✅ MIRAS framework released (December 2025)
✅ Internal testing in Gemini 1.5 Pro (long-context variants already show these traits)
Phase 2: Developer Preview (Q1-Q2 2026)
Stateful API endpoints: Instead of sending your full history every request, you’ll send a `session_id`. The model keeps its own learned state. You’re not paying for the redundancy.
Memory seeding: Upload a “memory file” to prime the model with domain knowledge or context that doesn’t expire per conversation. No more manual re-prompting.
MCP integration: Microsoft’s Model Context Protocol (which Google’s adopting across the ecosystem) becomes the standard way to feed learning events to Titans models. Tools, documents, and live data become first-class learning sources.
Phase 3: Consumer Integration (Late 2026 onwards)
Gemini Advanced: “ Remember that project you told me about 6 months ago?” The model actually *knows* without searching logs. It learned it into neural memory the first time you mentioned it, and it stuck.
On-device Titans: Compressed versions (Titan Nano) ship on Pixel 11, Chromebooks, even your laptop. The model learns your habits locally — your code style, your tone, your preferences — without uploading anything.
The death of context windows: We stop measuring in tokens. Instead: “Memory Retention Rate” and “Recall Accuracy.” Infinite context is table stakes.
Part 4: What This Actually Means for the LLM Landscape

I guess databases will be for our context
For Model Makers
- RAG becomes a learning mechanism, not a workaround. Instead of “retrieve text and stuff it into context,” the flow is: “retrieve text → run learning pass → update memory → answer.” You teach the model once; it retains concepts, not just text.
- Fine-tuning is dead. Test-time training replaces it. Why spend 2 weeks and $5K retraining when the model can learn from conversation?
- Context window anxiety vanishes. Token counting becomes obsessive. What matters is how well the model retained what you taught it.
For AI Infrastructure
- Session state becomes the moat. The value isn’t in the prompt anymore; it’s in the accumulated neural state of that session. You’re paying for compute, not token volume.
- Stateless APIs are obsolete. Expect endpoints with `session_id` as the primary key. Your context isn’t sent; it’s *held* by the model.
- MCP/Model Context Protocol is the new connector standard. Microsoft backed it. Google’s adopting it. This is how your tools, data, and documents become learning sources.
For Users (You)
- True personalization finally exists. The AI develops a relationship with you. It learns your style, your priorities, your blind spots — and keeps them.
- Privacy gets thornier. Test-time learning means the model changes based on what you tell it. If you keep telling it “the sky is green” with conviction, it might overwrite its beliefs. Data poisoning is real. Jailbreaking gets way more potent.
- You stop repeating yourself. No more copy-pasting context. The model builds a persistent understanding of your project, your voice, your requirements.
Part 5: How to Prepare Now (The Actionable Part)
Prompt Engineering without the context problem?
For Individual Users (Practitioners, Builders, Researchers)
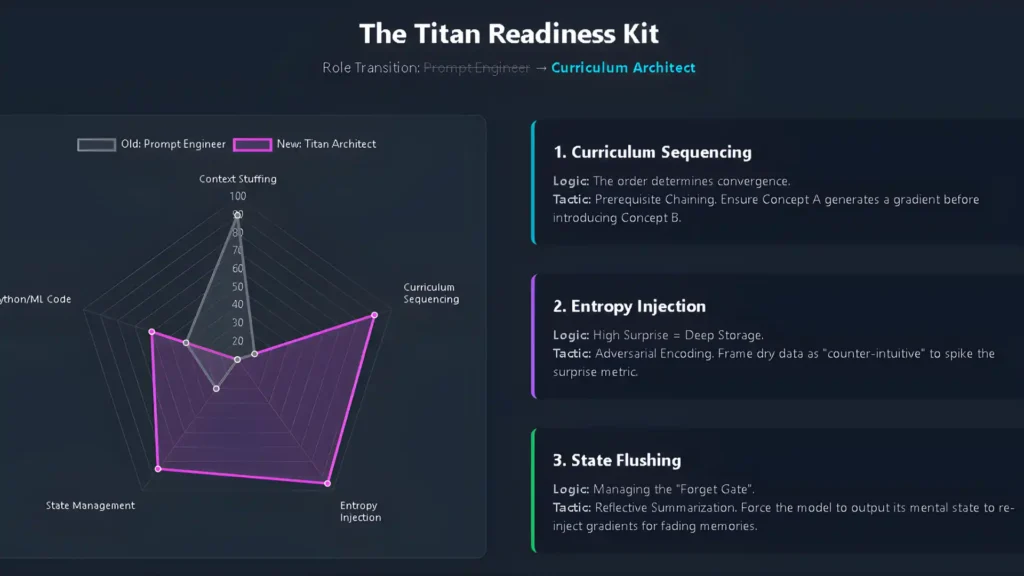
1. Stop Relying on RAG as a Crutch
- Start thinking about how to structure your knowledge as “ high-entropy learning events” instead of flat documents. – Instead of: “ Here’s a 50-page PDF about my company. Answer a question.”
- Try: “Here are the 3 core conflicts in our strategy. Integrate that understanding, then answer.”
- You’re manually simulating the “Surprise Metric.” Make your input dense, not long.
2. Adopt Chain-of-Density Prompting
- This technique (condensing information to its highest semantic density) is essentially preparing your input for Titans-class models.
- Less token waste. Higher signal. The model treats it as a legitimate learning event.
- Try CoD upgrade the Context Extension Protocol. It’ll be essential with Titans.
3. Prepare Your “Session Identity”
- Start thinking of your conversations as persistent sessions, not one-off interactions.
- Document what the model should remember about you:
- Your coding style, domain expertise, communication preferences
- Your project’s architecture, constraints, goals
- Your role in your team
- When Stateful APIs drop, you’ll seed this into your session, and the model will build on it.
4. Audit Your Data Sovereignty
- If the model learns from what you tell it and stores it as neural weights, you need to know what you’re teaching it.
- Set up a “learning consent protocol”: What’s safe to teach the model? What’s proprietary? What needs encryption?
- This isn’t paranoia. This is due diligence.
5. Start Treating Tool/Data Integrations as “Learning Pipelines”
- MCP servers (connectors to your tools, data, APIs) will become the primary way to feed information to Titans models.
- Instead of manual copy-paste, set up MCP connections to your:
- Codebase (Git, GitHub)
- Knowledge base (Notion, Confluence, Obsidian)
- Real-time data (Slack, emails, calendar)
- High-surprise updates flow automatically. The model learns from your actual work.
For Teams & Organizations
1. Build a “Memory Governance Framework”
- You can’t let models learn indiscriminately from your Slack, email, and databases.
- Define: What can be learned? Who can teach? When do memories expire?
2. Invest in Internal MCP Server Development
- Your ERP, CRM, knowledge base, codebase — these should have MCP connectors.
- This isn’t tomorrow’s problem. It’s today’s infrastructure play.
- Start small: Git repo → MCP server. See where it goes.
3. Rethink Your “Context Strategy”
- Stop building massive context-stuffing prompts.
- Build curriculum instead. Sequence what the model learns, in what order, with what intensity.
- This is what separates teams that leverage Titans from teams that just use a fancier GPT.
4. Prepare Your Prompts as “Learning Protocols”
- High-performing prompts will be less “give me a response” and more “here’s what I want you to internalize.”
- Structure: Domain primer → Learning events → Task
- Instead of hoping the model attends to your context, you’re teaching it.
5. Plan for Session Migration
- When Stateful APIs launch, you’ll want to migrate your key sessions and learned states across models.
- Start versioning your sessions. Start tracking what the model learns about your products, customers, and processes.
For AI Developers & Engineers
1. Start Building Test-Time Training Scaffolding
- Even on current models, you can simulate test-time learning through multi-turn conversation design.
- Build a “learning loop” that explicitly marks certain turns as “encode this” vs. “use this to answer.”
- When Titans models drop, your abstractions translate.
2. Design for Stateful Sessions
- Don’t assume stateless APIs. Architect for `session_id` as first-class.
- Store session state separately from model state.
- Build migration tooling now.
3. Experiment with MCP
- Microsoft’s MCP is already live (Copilot Studio, Windows 11, GitHub Copilot).
- Build test servers. Connect them to your tools.
- When Google standardizes on MCP for Titans, you’ll have patterns ready.
4. Prepare for Gradient-Based Learning at Inference
- Read about online gradient descent, Hebbian learning, and meta-learning.
- This is the math underneath Titans. Understanding it now means you can design better prompts and learning protocols.
- Start experimenting with “surprise-aware” input scoring.
5. Invest in Memory Audit & Tracing
- If models are learning weights at inference time, you need visibility.
- Can you trace what the model learned from each interaction?
- Can you revert a learning event if it was poisoned?
The Call to Action: What You Do Monday Morning
Pick one of these, based on your role:
If you use AI daily (writer, researcher, coder, analyst):
→ This week, consciously structure one prompt using Chain-of-Density principles. Compress information to its densest form. Notice the difference in output quality. Then start doing it everywhere.
If you lead a team:
→ Schedule a 30-minute sync with your CTO/technical lead. Discuss: “How do we prepare for models that learn during conversation?” Assign someone to explore MCP. Start a memory governance doc.
If you build AI products or services:
→ Shift one experimental feature from “context stuffing” to “learning protocol.” Design it. Test it. See what works. This is your unfair advantage when Titans goes production.
If you’re an AI researcher:
→ Read the MIRAS framework paper. Implement a test-time training loop on an open-source LLM. Publish your findings. You’ll be ahead of the market by 12–18 months.
The Closing Truth
Titans doesn’t make AI smarter. It makes AI learnable. And that changes everything.
The question isn’t whether this happens. It’s whether you’re ready when it does. The cycle breaks when we stop treating AI as a tool and start building it as a partner. That era starts now.
Leave a Reply