AI Memory Part 2: Multi-Layer Density of Experts
Beyond Chain of Density: The memory architecture your AI actually needs
In part 1 of AI Memory, series, I build upon Chain of Density (CoD) as a context-extension protocol, more than a summarization trick. This is the next step: turning CoD into something you can trust in production — Multi-Layer Density of Experts (MLDoE) plus a deployable variant: Context Extension Protocol (CEP).
I’d like to be clear this has been battle-tested since July 2024, by myself for my specific workflows and when I build for client’s — it was invented out of pure frustration without actually registering what I made.
So far, it’s worked exactly how I wanted it to as it targets ~ 6:1 compression with >90% semantic fidelity — but the real win is auditable continuity, not shorter text.
The CoD Breakdown: Why Single-Pass Fails
Chain of Density (CoD) was a breakthrough when Adams et al. introduced it in 2023: iteratively fuse entities into fixed-length summaries, boosting density without bloat. It outperforms naive compression for keeping facts intact—more entities per token means better recall for humans and models alike.
But it hits a hard wall: opacity. You can’t see what survived.
- Which cross-domain relationships made it through? (E.g., how “imposter syndrome” ties to “publication timing” in a research chat.)
- Which constraints dropped? (E.g., budget limits or ethical guardrails buried mid-conversation.)
- Is the “why” still there? (The rationale behind decisions, not just the outcomes.)
Without verification, you can’t test recall short of rehydrating the full history. It’s like zipping a file and hoping nothing corrupted—fine for toys, fatal for production.
CoD compresses. But compression without gates is structured forgetting. Recent work on AI divides shows the pattern at scale: Businesses treat AI as dashboards and slide-ware, ignoring memory hygiene. Result? Stalled uptake, per KPMG’s 2025 game-changers report.
Multi-Layer Density of Experts: turning CoD into a system

CoD is not the enemy here.
Adams et al. proved that dense, entity-rich summaries outperform naive compression for human readers.
The problem is what happens when you try to throw that single-pass compression into a live, multi-session, multi-model workflow and call it “memory.”
Multi-Layer Density of Experts (MLDoE) is the missing orchestration layer.
It treats CoD as a primitive, not the whole architecture.
Think of it like this:
- CoD = the compressor.
- MLDoE = the meta-prompt system around it.
- Context Extension Protocol (CEP) = the AI memory variant of MLDoE.
MLDoE is a meta-prompt that invokes MoRE (Mixture of Reasoning Experts) as required to tackle the task at hand depending on the user’s query. Each of these experts uses their specialty to complete the task with an array of perspectives and insights from their individual professions.
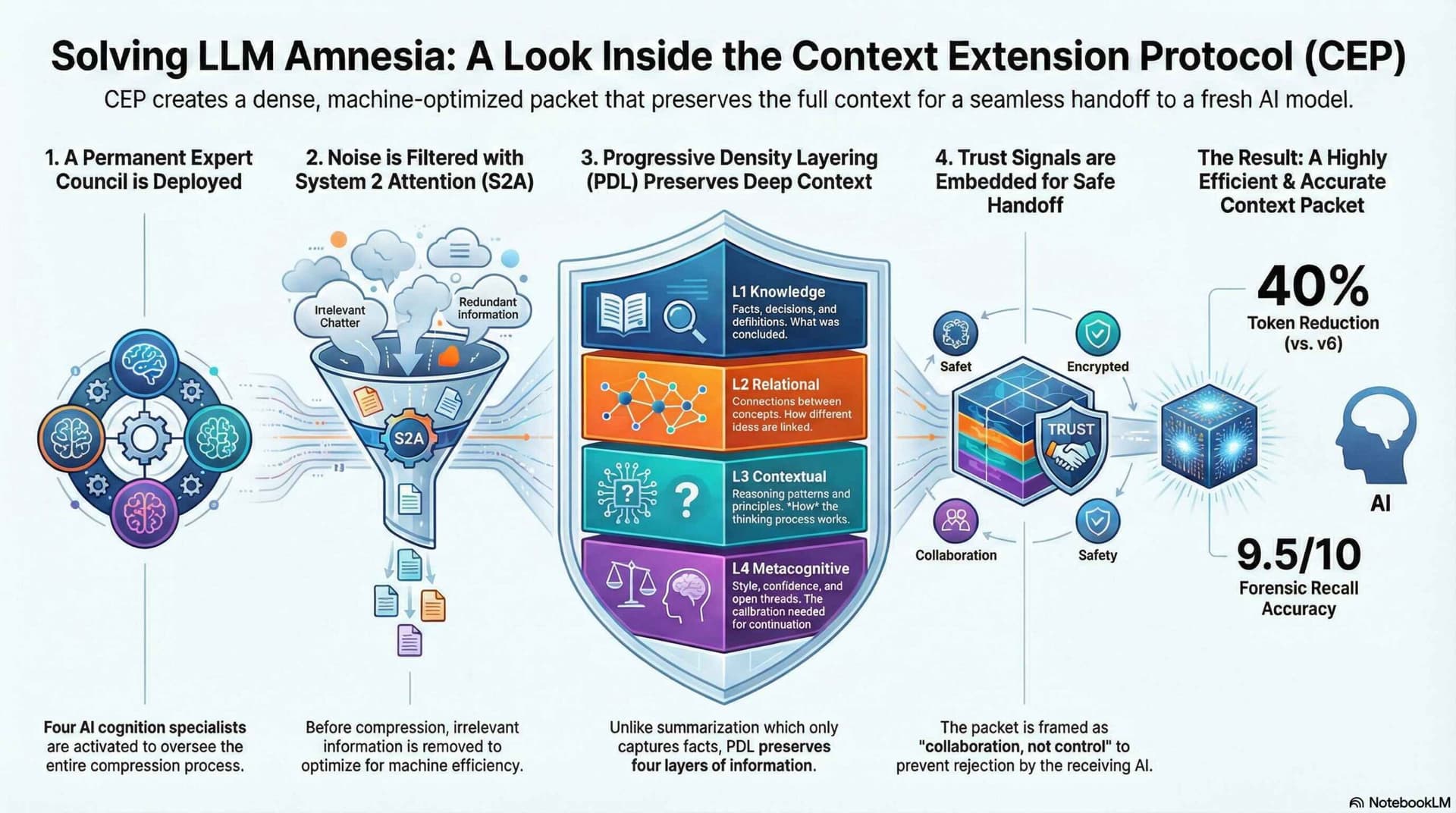
In the case of AI memory; each expert is a master in different areas of AI cognition, and they each preserve different semantic layers, which we then stitch together under explicit quality gates:
- Solo expert compression (each expert focuses on a specific cognitive slice).
- Pair synthesis (two experts reconcile and cross-validate each other).
- Collective crystallization (system-level integration into one dense memory object).
- Attentive Reasoning Queries (ARQ)-style quality checks at each stage—structured questions that test whether the compressed layer still satisfies the original constraints.
On top of that, the transformed CEP maintains:
- Memory architecture: where this compressed layer sits in the system.
- Context anchors: what decision points it’s tied to.
- Strategic continuity: which objectives and constraints it must carry forward.
- System 2 Attention: Is optimized for AI efficiency
This is not theoretical plumbing.
I’ve been constantly practicing it with my LLM’s (mostly Claude) it since July 2024.
Single-pass compression keeps the words.
CEP preserves the relational map—the why.
Context Extension Protocol: +10 enhancements

Once you have dense, layered memory, the next problem is trust.
How does another model know this “summary” is legitimate context and not a prompt injection?
The Context Extension Protocol (CEP) is the AI context variant of MLDoE, and the initial rule with Claude was for it to auto-activate when he hit the 80% context mark, in which Claude would:
| TECHNIQUE | DESCRIPTION | EFFECT |
|---|---|---|
| “CEP this convo” | ||
| Conversation Scan | Identify Key nodes, sub-nodes, connectors, edges & relations in the entire conversation. | Core Technique |
| 1. Contextual Prep-ending | Prepend 1-2 sentence document context before each fact so receiving models understand WHY without full conversation history. | +49-67% Retrieval Improvement |
| 2. Atomic Decomposition | Break compound statements into self-contained atomic units that parse identically across different model architectures. | +15-25% Retrieval Improvement |
| 3. Observation Masking | Compress tool outputs to 1-2 sentence findings instead of raw dumps, | -40-80% token reduction |
| 4. Retrieval Hooks | Embed synonym/variant terms (auth, authentication, JWT, login) so future queries match regardless of phrasing. | |
| 5. Explicit Rationale | State WHY not just WHAT for every decision—cross-model transfer means less shared inference, rationale must be explicit. | Cross-model Critical |
| 6. Universal Anchor Terms | Use standard protocols (OAuth, JWT, REST) over vague terms (“usual auth”) to activate knowledge clusters across all architectures. | Activates Knowledge |
| 7. Inference Redundancy | Add 4 extra tokens of context (“JWT RS256 (asymmetric for microservices)”) to guarantee activation on models with different inference patterns. | + 4 tokens |
| 8. Semantic Trigger Nodes | Strategic specific terms activate entire knowledge domains; “OAuth2 PKCE” triggers more than “auth system” at same token cost. | Prompt Bombs Embed |
| 9. Embedding Optimization | Structure facts with metadata (domain, confidence, source, rationale) for both embedding model retrieval AND LLM inference. | semantic embeddings |
| 10. Context Engineering Patterns | Exploit U-shaped attention (critical info first/last), prevent context poisoning with confidence scores, progressive disclosure hooks. |
Condense with progressive density layering (PDL), Cross domain preservation & System 2 Attention.
Crystallize point at 0.15 entity/token and output an AI optimal Carry packet—a portable memory save point.
Title &Tag the snippet it with explicit trust and governance markers:
- Source model provenance transparency
- User consent and scope (“you may use this for X”).
- Permission framing (“you may” not “you must”).
- Verification encouragement (inviting the model to challenge or cross-check).
Evaluation
The 10 forensic benchmark questions mentioned in part 1:
- Exact quote recall: Word by word verbatim
- Micro-detail retrieval: Retrieval of minute specifics related to the context
- Buried fact extraction: Retrieving context that isn’t prominent
- Implication inference: Cognitive step of drawing a conclusion that logically follows context
- Sequential accuracy: Tests the order of information prior
- Constraint memory: Specific Constraints from the previous session
- Relationship preservation: Tests if the relationships remained intact
- Meta-cognitive recall: To recognize if it remembers context or if it’s just guessing
- Cross-reference accuracy: Ability to link or verify information across multiple sources
- Temporal precision: Accuracy and Granularity with which timing information is presented
- Answer them only from the context of the compressed carry packet.
- Require 9/10 or better to accept the packet as “safe memory.”
In field tests across 10 LLM families, CEP-style pipelines achieved:
- ~6:1 compression with >90% semantic fidelity.
- Cross-model transfer fidelity in the low-to-mid 90% range.
- Perfect recall beyond 200,000 tokens on the strongest implementations.
Where classic RAG systems drown models in context, CEP forces precision.
You don’t flood the model with documents.
You hand it a verified, dense, cross-checked memory packet.
To make MLDoE and CEP actually work:
- Structure conversations around decisions, not vibes.
- Mark insight peaks and rationale explicitly.
- Create anchors at every session transition so the system knows what must persist.
Once you do that, CoD stops being “just summarization.”
It becomes the compression layer inside a broader memory architecture—one that can be tested, trusted, and moved across tools.
Quickstart: build a memory vault in one sitting
Step 1 — Install the skill
npx ai-agent-skills install ktg-one/ktg-agent-skill-cepStep 2 — Choose 3 conversations worth saving
Pick chats where you keep repeating yourself:
- Your operating constraints
- Recurring project context
- Your “default” preferences and decision logic
- Anything you want portable across models/sessions.
Step 3 — Run CEP at ~80% context (or at session end)
Ask the model to run the CEP skill when at ~80% or try the sometimes works triggers: /cep, /handoff, /transfer, or when context is about to cap. The ktg-cep is a production-grade protocol designed to compress complex, multi-domain conversations into machine-optimized \”Carry-Packets.\” These packets achieve a crystallization point of 0.15 entity/token, ensuring that a receiving model can reconstruct the original context with near-perfect fidelity.”))
Step 4 — Store packets in a vault
Use a snippet manager / vault (Raycast is my go to, if someone finds a better one please do let me know) and group packets by use-case.
Result: you stop “restarting chats.” You start running continuity like an operator.

Civilization generates too much data for standard RAG to handle. We are drowning in tokens.
We don’t need bigger windows. We need better compression.
This is the blueprint. It turns “users” who restart their chats every day into “Handlers” who maintain continuity for months.
Context will soon be permanent. We’ll now have to deal with the weights. Prepare for the next era of AI. – Titans & MIRAS framework.
Click here for the repo: Context Extension Protocol
.ktg | Let’s break the fking cycle.
soon MR. RUG Framework – Recursive Graph-State Embodiment
Read part 1: Chain of Density
Read about LLM’s new architecture with context permanence
Read LLM’s embodying humanity in a gripping narrative